图像渲染管线理解

Render 关键词
-
渲染 (Render) 直译就是绘图或图像可视化,只是这个过程是由软件参与,在PC或移动端上生成或展示图像。
图像渲染是 CG 技术的子学科,其他几个兄弟学科有 几何、动画、物理仿真等。渲染本身包括 2D 渲染和 3D 渲染。
-
图形 API 标准/框架 图形 API 是 CPU (Host) 交互 GPU (Device) 的接口,不是指特定的代码库,而是一套 API 规范,各家显卡厂商按照规范,实现自己的GPU驱动。
业内常用的图形API有以下:
OpenGL :-
OpenGL规范由1992年成立的OpenGL架构评审委员会(ARB,Architecture Review Board )发布,2006年将控制权传递给了 Khronos Group ;
-
OpenGL不仅语言无关,而且平台无关;
-
OpenGL ES(OpenGL for Embedded Systems)首次发布于2003年,是OpenGL子集,为移动端而生,相对于OpenGL去除了一些非必要的且性能欠佳的一些API;
-
WebGL来在网页上绘制和渲染复杂三维图形,基于 HTML 和 JavaScript 开发;
-
不同平台上有不同的机制一关联Native窗口系统,在Windows上是wgl,在X-Window上是 xgl,在Apple OS上是 AGL/ EAGL, Android 上是 EGL ,还有些可以方便 OpenGL 接入 Native 窗口的第三方库 freeglut, GLFW , SDL , Qt, wxWidgets等等;
-
除了核心API要求的功能之外,GPU 供应商可以通过扩展的形式提供额外功能,扩展可能会引入新功能和新常量,一般以 EXT_ 开头,也有以厂家缩写开头的(举例如GL_NV_bindless_texture);
-
OpenGL 现在广泛使用的大版本有 OpenGL 3,4, GL ES版本有 ES2, ES3,版本之间接口可能有新增或去除,以及规范中的兼容性要求,都可以在 https://docs.gl 进行查询;
-
最新版本是 2017 年发布的 OpenGL 4.6,可能不久的将来就停止更新了(Khronos 要发力 Vulkan);
-
- Direct3D:
-
Direct3D 是微软公司开发的图形API,不能跨平台,只能在 Windows 上运行;
-
Direct3D 是 DirectX 的一部分,所以也会以 DX+数字 来指代Direct3D 具体版本,例如简称DX11或D3D11都可;
-
开发引入可以采用COM interface,也可以采用 .NET Framework;对于COM interface,遵循COM规范编写,以Win32动态链接库(dll)或者可执行文件形式发布;
-
COM 优点:与开发语言无关、通过接口有效保证了组件的复用性、组件运行效率高,便于使用和管理;
-
自 1996 年首次发布以来,目前最新版本已经到了 Direct3D 12;
-
- Metal:
-
Metal 是由苹果公司所开发的图形API,2014 年发布,兼顾图形与计算功能,支持面向底层、低开销的硬件加速,类似于兼并了 OpenGL 和 OpenCL,同时支持 GPU 加速的 3D 图形渲染和并行数据计算;
-
只能在 Apple 的 MacOS / iOS 上运行;
-
使用 Objective-C 或 Swift 开发,最新版本已经来到了 Metal 3.0 (WWDC 2022: Discover Metal 3);
-
- Vulkan:
-
Vulkan是Khronos Group开发的一个新 API ,它提供了对现代显卡的一个更好的抽象,与OpenGL和Direct3D等现有 API 相比,Vulkan可以更详细的向显卡描述你的应用程序打算做什么,从而可以获得更好的性能和更小的驱动开销;
-
Vulkan的设计理念与 Direct3D 12 以及 Metal 基本类似,但 Vulkan 作为 OpenGL 的替代者,它设计之初就是为了跨平台实现的,可以同时在 Windows、Linux 和 Android 开发,以及在 MacOS/iOS 也可正常工作,只是底层基于 MoltenVK 实现的;
-
目前最新 Stable release 版本是 1.3.245;
-
- 软件渲染:如 Mesa 3D 图形库、 SwiftShader 以及各类开源库;
- API 之间的模拟: ANGLE、 Zink、 WineD3D、 dxvk、 VKD3D、 MoltenVK;
-
Shader Shader 也叫着色器,是运行于GPU的代码片段,语法简单,有点像简化版的C/C++语言,外加一些渲染或并行计算特有的数据结构和用法;
OpenGL下称为 glsl 代码,D3D 称为HLSL,Metal 下称为 metal 代码,其实后缀都无所谓,基本都是字符串读入,由特定图形 API 的 compile 接口编译成 GPU 能识别的指令序列。
-
实时与离线 这是渲染的两大分类:
- 实时渲染(Realtime Rendering)是指渲染到屏幕,也就是我们说的预览,对实时性要求高,每帧处理时间不得高于 1.0/fps 秒(fps, frame per seconds),会配合 Double Buffer 技术使用(渲染中属于 Swap Chain 一环,有时也会使用 Tripple-Buffer);
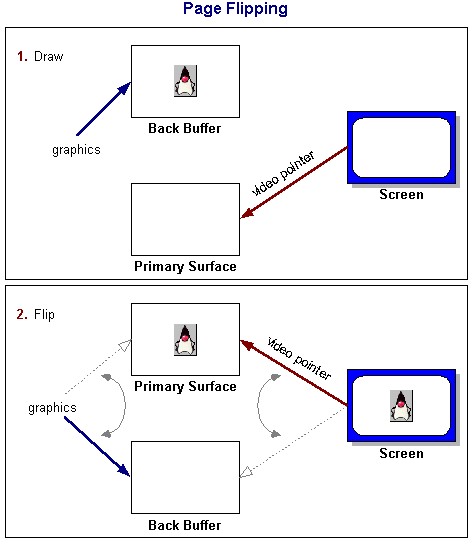
- 离屏渲染(Offscreen Render)是指某些时候我们不需要将渲染结果显示在屏幕,那我们选择保存到文件或渲染到 FrameBuffer/ Texture 暂存,平时我们说的视频导出了,对实时性要求没有预览那么高;
-
渲染引擎
- OSG
- Ogre
- Bgfx
- DiligentEngine
- Filament
- Oryol
- Cesium.js,Three.js
- 内含于游戏引擎:Unity 3D, Unreal Engine, Cocos 2D&3D ……
-
工业应用
主流工业应用:包括电子游戏、AR/VR/MR、流媒体影视 、计算机辅助设计/工程(CAD/CAE)、仿真模拟、动画电影特效以及其他可视化设计。
管线概览
渲染的过程称之为渲染管线(Render PipeLine)。
渲染管线的主要功能是基于给定的虚拟相机、物体、光源、照明模式以及纹理等诸多条件的情况下,生成或绘制一幅二维图像的过程。
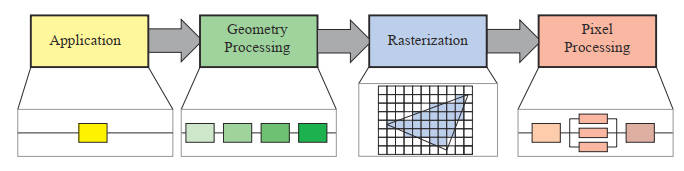
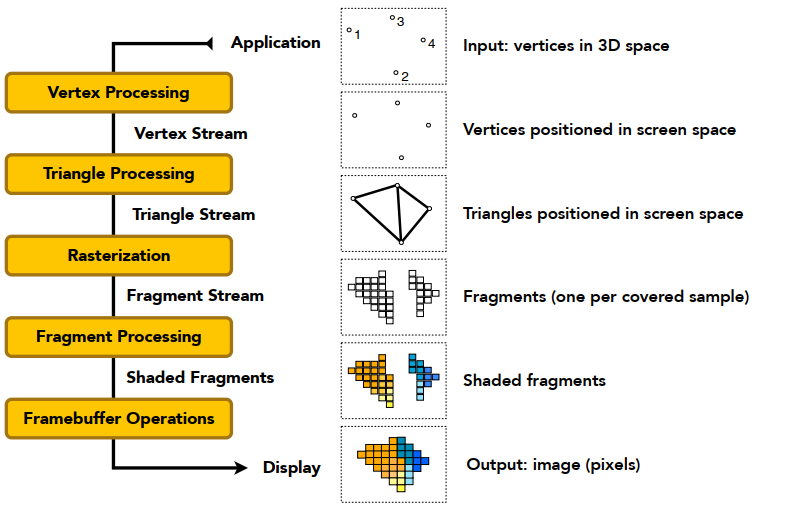
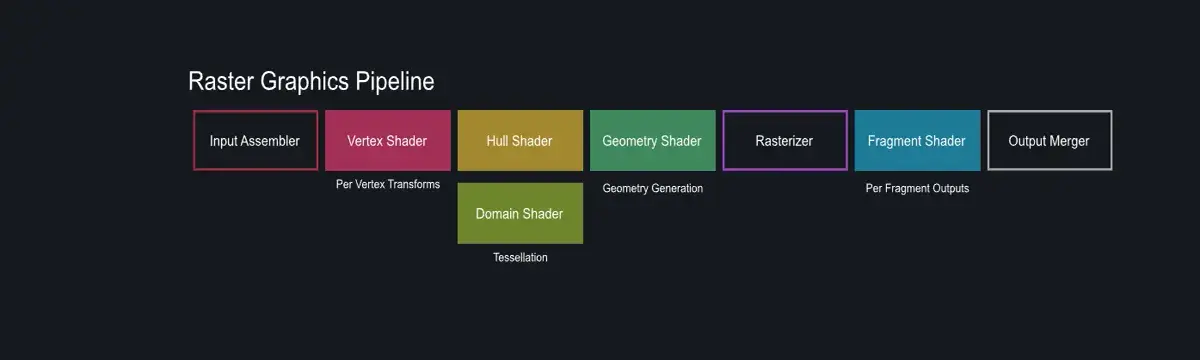
在概念上可以将图像渲染管线分为三个阶段:应用程序阶段、几何阶段以及光栅化阶段。
-
应用程序阶段(The Application Stage):开发者完全控制,CPU参与,几何体数据准备(包括点、线、矩形等绘制图元 — render primitive),虽然是个单独的过程,但是仍然可以进行管线化或者并行化处理。
-
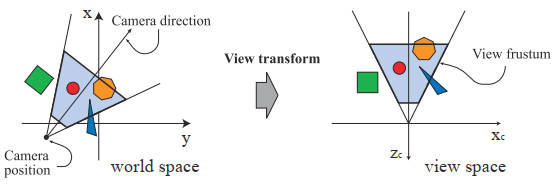
几何阶段(The Geometry Stage):负责大部分顶点、多边形操作。

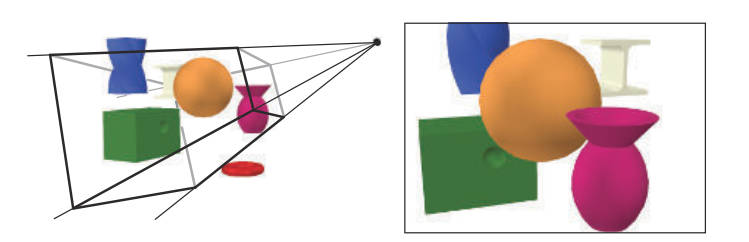
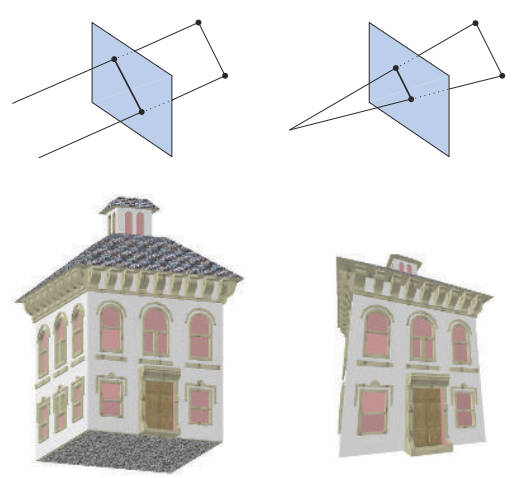
如上图所示,该阶段包括模型&视点变换、顶点着色、投影、裁剪、屏幕映射,几何阶段执行的是计算量非常高的任务。下图为模型视点变换对相机和模型的影响:
两种投影形式(相机类型)如下图:
裁剪 Cliping 过程如下图:
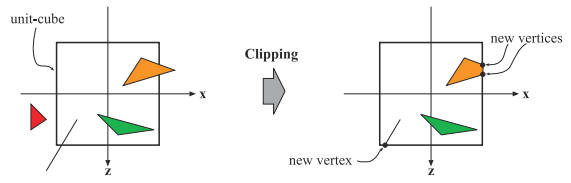
对部分位于视体内部的图元进行裁剪操作,这就是裁剪过程存在的意义。
-
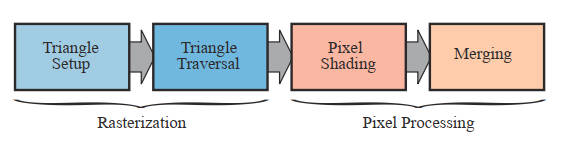
光栅化阶段(The Rasterizer Stage) :给定经过变换和投影之后的顶点,颜色以及纹理坐标(均来自于几何阶段),给每个像素(Pixel)正确配色,以便正确绘制整幅图像。这个过个过程叫光珊化 (rasterization) 或扫描 变换( scan conversion),即从二维顶点所处的屏幕空间(所有顶点都包含 Z 值即深度值,以及各种与相关的着色信息)到屏幕上的像素的转换。
光栅化可以细分如下:
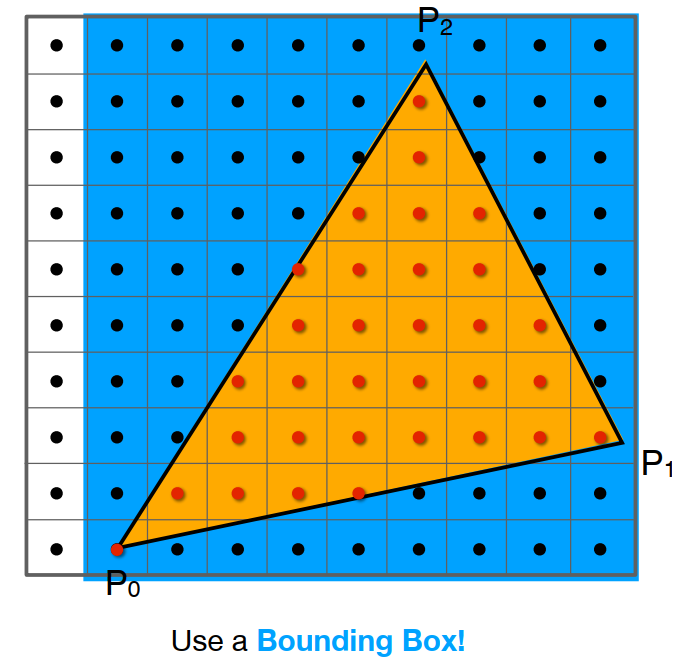
其中,在三角形遍历阶段将进行逐像素检查操作,检查该像素处的像素中心是否由三角形覆盖,而 对于有三角形部分重合的像素,将在其重合部分生成片段( fragment)。
我们实际获得了 👇 ,What happend?Sampling Aliasing !
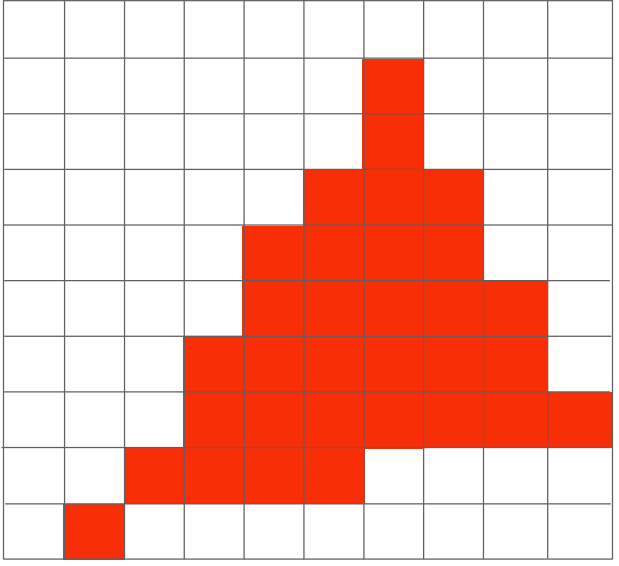
抗锯齿采样手段如下:

抗锯齿采样结果如下:
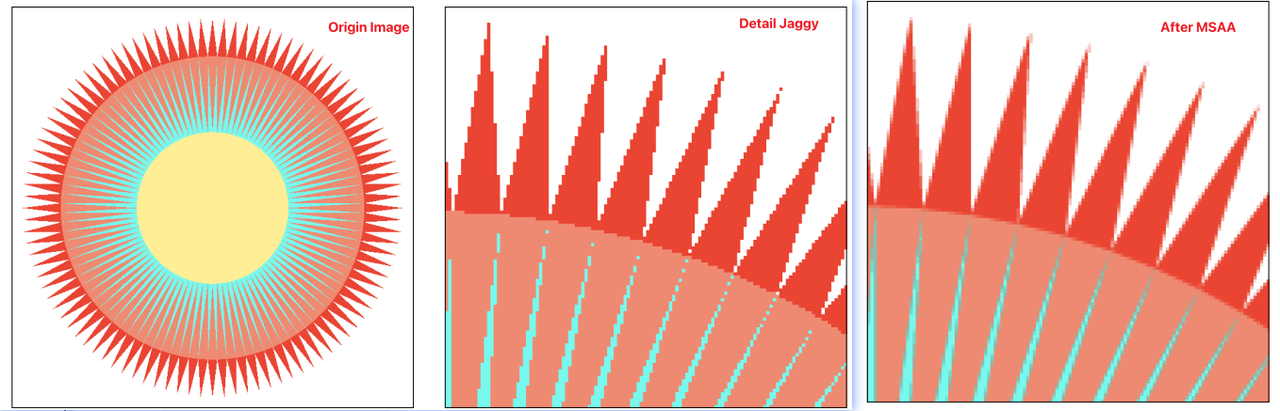
面对这种采样失真的情况,需要应用反走样技术(也叫抗混叠),常用的技术为多重采样抗锯齿(Multi Sampling Anti-Aliasing,简称 MSAA),是一种特殊的SSAA(Super Sampling AA,简单放大后近邻混合)。
MSAA 首先来自于 OpenGL。具体是 MSAA 只对 Z 缓存(Z-Buffer)和模板缓存 (Stencil Buffer)中的数据进行超级采样抗锯齿的处理。可以简单理解为只对多边形的边缘进行抗锯齿处理。
其他抗锯齿的手段还有很多,例如 CSAA, HRAA, TXAA,MFA,FXAA等等。
此外,得到的 fragment 像素的深度 (距离观察相机的远近,即 Z-Buffer)各不相同,需要做一次深度测试,来决议可见性的问题,保留 near 去除 further,效果类似于 “画家算法”。
最后,三个主流程串联起来,关键步骤如下:(注意某些步骤的 Programmable 、 Configurable 或 UnConfigurable)
图形 API 工作机制
OpenGL
关于OpenGL机制,最广为人所知的是它是一个状态机(State Machine ,如下图,高清原图看OpenGL State Machie Schematic),不对应任何驱动具体实现,只是大致的原理图。
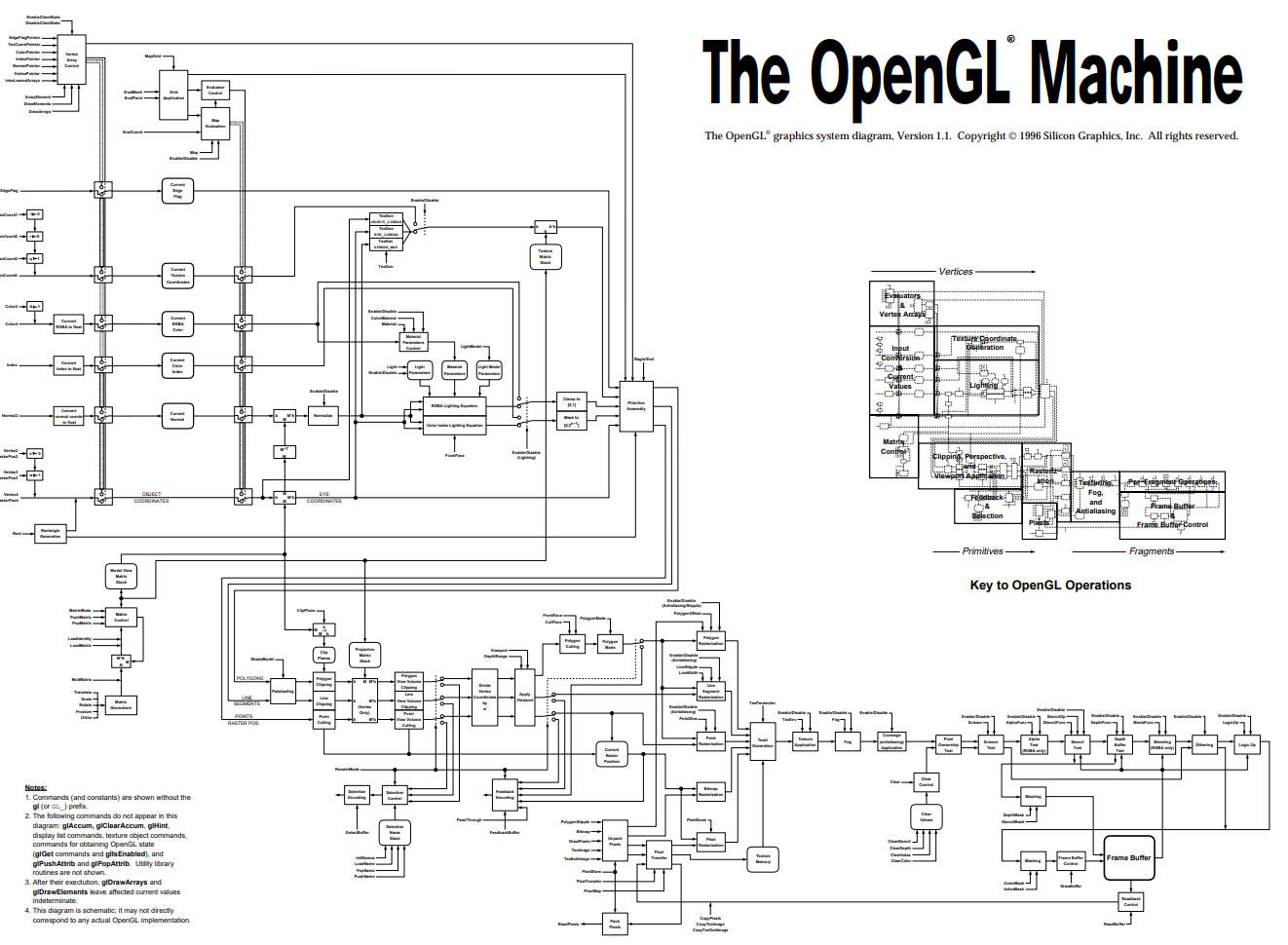
说到 OpenGL 不得不提的是其上下文机制 (Context),在应用程序调用任何 OpenGL 的指令之前,需要安排首先创建一个 OpenGL 的上下文。这个上下文是一个非常庞大的状态机,保存了 OpenGL 中的各种状态,这也是OpenGL指令执行的基础。
虽说可以在不同线程中使用不同的Context,Context之间共享纹理、缓冲区等资源,利用 Shared Context 减轻上下文切换的负担(配合glFence),但是能共享的资源类型是有限制的(例如FBO 和 VAO 属于资源管理型对象,不可共享)。
但出于OpenGL 由于状态机这个桎梏,天然是适合单线程渲染的。由于状态机中的状态、资源、内存无法解决多线程中的竞争问题,在OpenGL中实现多线程一直是荆棘中跳舞,就算再小心翼翼也不能避免刺痛。
我们的渲染资源的操作必须在其相应的渲染线程完成,避免破坏上下文。
Direct3D
Direct3D的重要抽象概念包括 devices, swap chains 和 resources。
-
devices 包括硬件设备(hardware device)、参考设备(reference device)、软件驱动设备(software driverdevice)、WARP设备(WARPdevice)以及其他 device type;
-
swap chains(交换链) 在Direct3D中为一个设备渲染目标的集合。每一个设备都有至少一个交换链,一个交换目标可以为一个渲染和显示到屏幕上的颜色缓存; 前后台缓存组合 (double buffering 或叫 page flipping),主缓存中的内容(前台缓存)会显示在屏幕上,而辅助缓存(后台缓存)用于绘制下一帧;
-
resources(资源)包含以下类型的数据:几何图形、纹理、缓冲区以及着色器数据**;**
下图 Direct3D Rendering Pipeline ,与标准 Pipeline 相比,有其定制化的内容,更为丰富,而且某些 stage 是可选的。
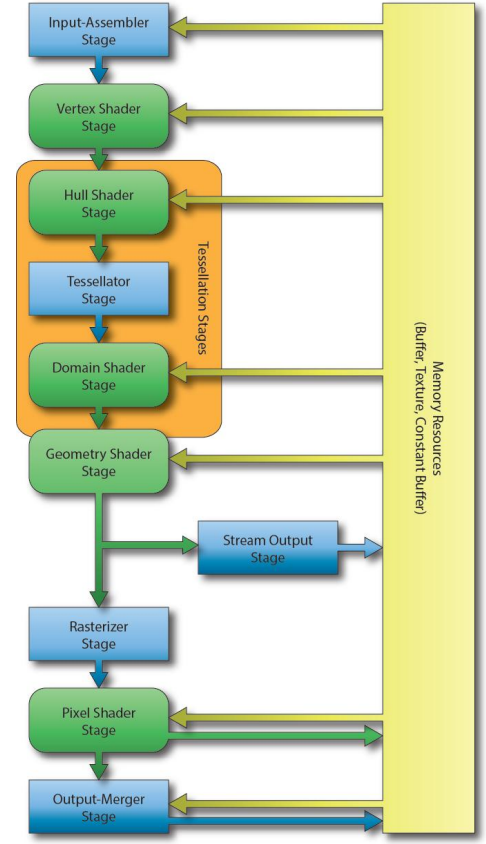
-
图中橙色的 Tesselation Stages 是曲面细分之意,单词原意是【镶嵌】,主要手段是对三角面进行细分,让渲染对象的表面和边缘更平滑,物件呈现更为精细。
-
Tesselation 是渲染管线中可选的阶段,并且该技术不是 Direct3D 独有(OpenGL 也有TCS - Tessellation Control Shader),只是Direct3D 单独为其增加了 3 个Shader阶段,分别是外壳着色器(Hull Shader,可编程)、镶嵌器 (Tessellator,不可编程,硬件管理)和域着色器(Domain Shader,可编程) 。
Vulkan
Vulkan 作为 Khronos 组织首推的下一代图形 API 规范,具有3个很明显的特点:
- 更依赖于程序自身的认知:让程序有更多的权限和责任自主的处理调度和优化;
- 多线程友好:让程序尽可能的利用所有CPU计算资源从而提高性能。Vulkan中不再需要依赖于绑定在某个线程上的Context,而是用全新的基于Queue的方式向GPU递交任务,并且提供多种Synchronization的组件;
- 强调复用:从而减少开销。大多数Vulkan API的组件都可以高效的被复用;
值得注意的是: Vulkan 不是万能灵药,一般来说,只有瓶颈在 CPU,将 OpenGL 改为 Vulkan 才有较大收益。
渲染的大致流程 :
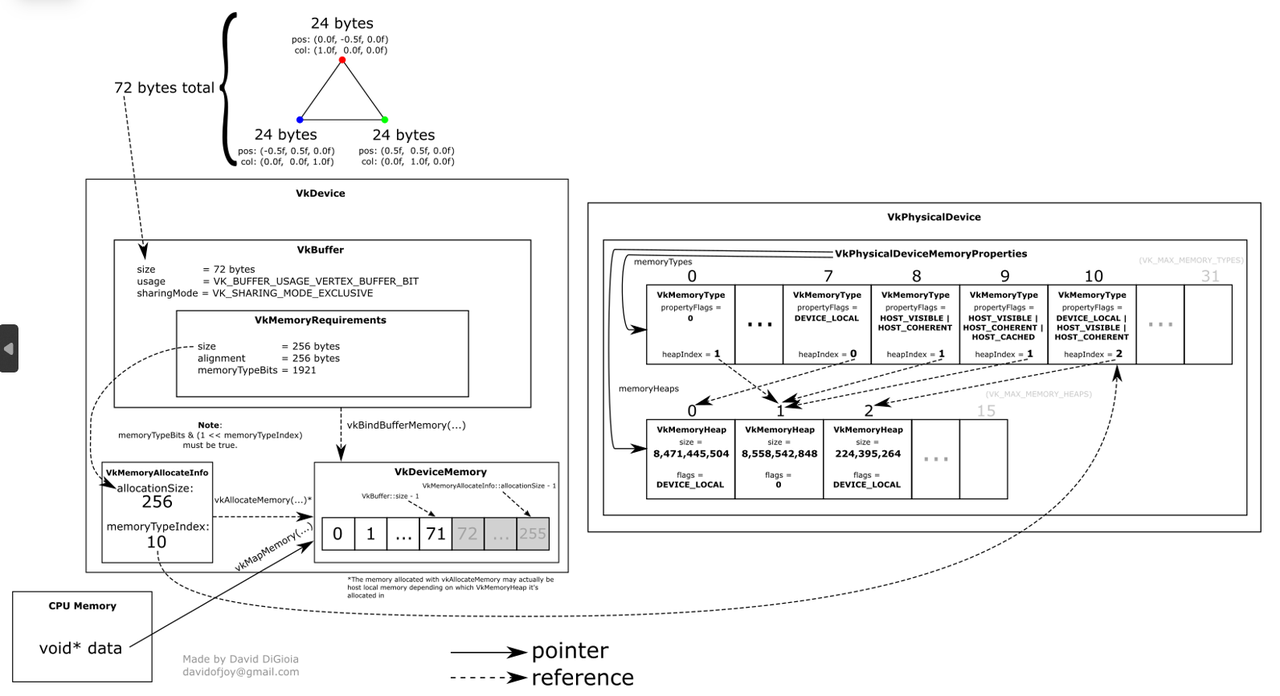
vkInstance $\rightarrow $ vkDevice $\rightarrow $ vkImage/vkBuffer$\rightarrow $ vkAllocateMemory $\rightarrow $vkBindBuffer/Image $\rightarrow $VkCommandBuffer $\rightarrow $vkQueueSubmit$\rightarrow $ vkPipeline + vkShaderModule$\rightarrow $VkDescriptorSet (bind model)$\rightarrow $VkSwapchainKHR $\rightarrow $vkQueuePresentKHR。
关于 Vertex Buffer 的申请,可以参考下图:
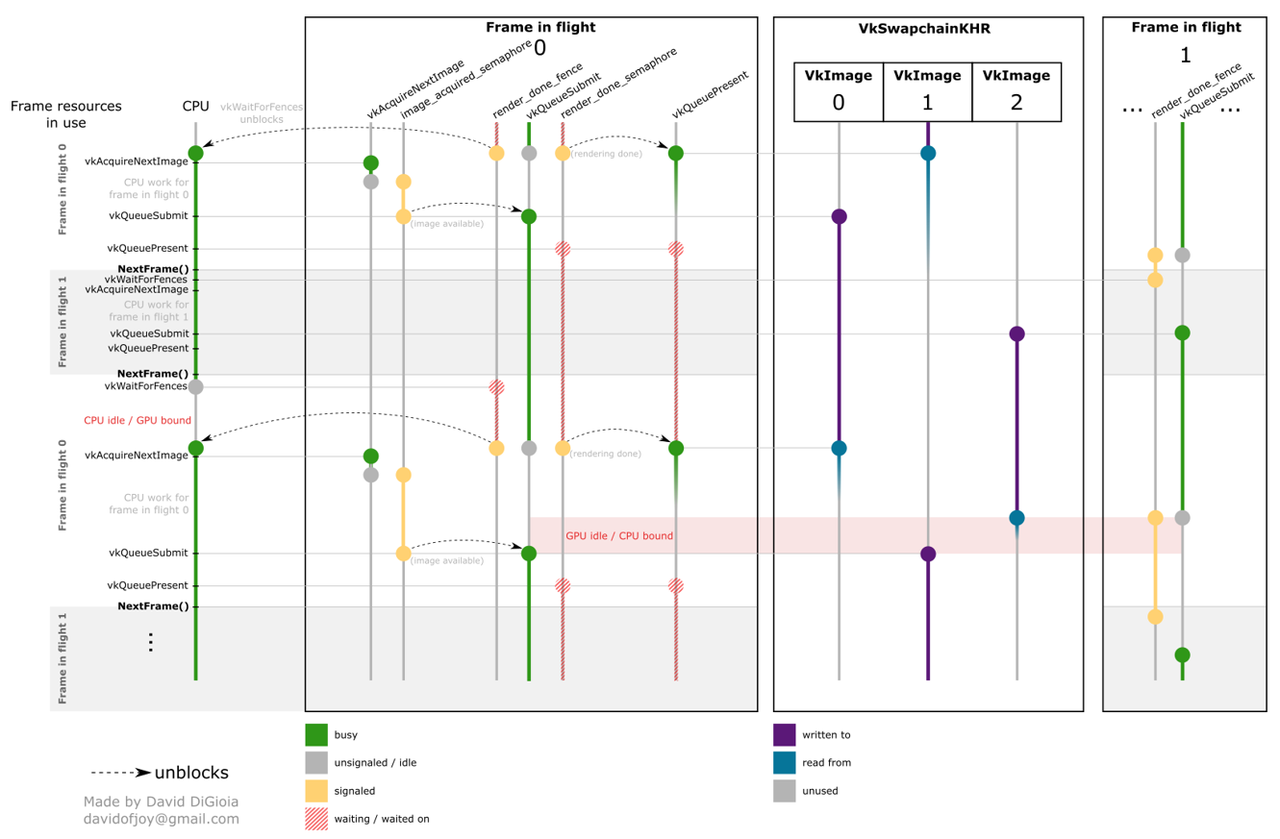
对于 Render Loop 的流程理解,可以参考下图:
验证层的常见操作有:
-
根据特性 Specification 检查参数值,以检测误用
-
跟踪对象的创建和销毁过程,以查找资源泄漏
-
通过追踪线程调用源头来检查线程安全性
-
将所有调用及其参数保存到标准输出
-
追踪Vulkan调用,用于剖析和重演
更多的 Vulkan 流程图理解可以参考一个 GitHub 仓库:David-DiGioia/vulkan-diagrams
Metal
Metal 作为现代图形 API 框架,设计上许多地方都和 OpenGL 不同,并与 Vulkan 较为相似,其渲染管线如下图所示:
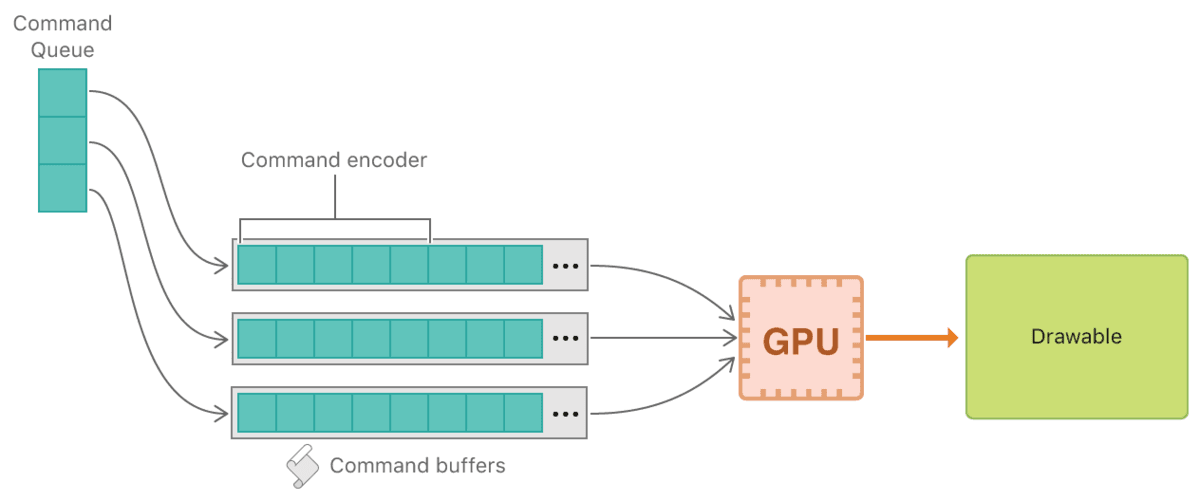
与 Vulkan 相似,有 MTLDevice、MTLCommandBuffer、MTLTexture、MTLCommandEncoder、MTLRenderPassDescriptor等资源,同步方面也有 addCompletedHandler、addScheduledHandler、addMTLFence、MTLEvent 的 Low-Level 的细粒度方式。
一个command queue包含了一系列command buffers。command queue用于组织它拥有的各个command buffer按序执行。一个command buffers包含多个被编码的指令,这些指令将在一个特定的设备上执行。一个Encoder可以将绘制、计算、位图传输指令推入一个command buffer,最后这些command buffer将被提交到设备执⾏。
各家 API 的理论性能极限
图形程序的性能表现和程序设计与流程息息相关,但 API 设计机制本身有别,倘若尝试一较高下,Khronos给出了一张各个图形 API 理论极限性能对比:

Hello Pipeline (OpenGL 为例)
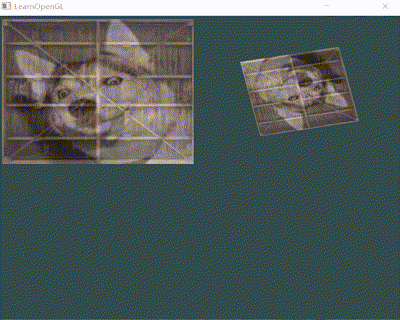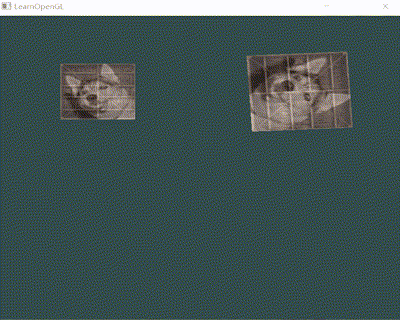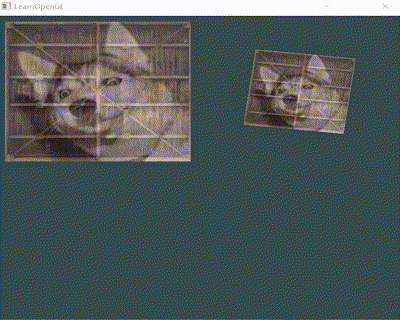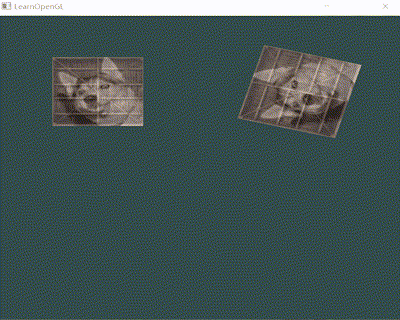
以一段简单的渲染 demo 为例,从 Render Pipeline 看下如下效果(2张图片上传、融合并缩放/旋转)是如何达成的:
-
顶点数据准备
指定一个矩形4个点的顶点数据,包括 3d-position、rgb-color 以及 texture-position:
1 2 3 4 5 6 7 8 9 10 11 12 13// Set up vertex data (and buffer(s)) and attribute pointers. (复合demo,颜色在这个效果可以不用,是其他效果的) GLfloat vertices[] = { // ---- 位置 ---- ---- 颜色 ---- - 纹理坐标 - 0.5f, 0.5f, 0.0f, 1.0f, 0.0f, 0.0f, 1.0f, 1.0f, // 右上 0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f, 1.0f, 0.0f, // 右下 -0.5f, -0.5f, 0.0f, 0.0f, 0.0f, 1.0f, 0.0f, 0.0f, // 左下 -0.5f, 0.5f, 0.0f, 1.0f, 1.0f, 0.0f, 0.0f, 1.0f // 左上 }; GLuint indices[] = { /* vertices的顶点索引 0,1,2,3 */ 0, 1, 3, // First Triangle 1, 2, 3 }; -
上传顶点数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28/*接收原始数据,并绑定属性到openGL上下文*/ void ProcessBindAttrs(GLuint& VBO, GLuint& VAO, GLuint& EBO, const GLfloat * vertices,GLuint vertexMemSize, const GLuint * indices,GLuint indexMemSize){ glGenVertexArrays(1, &VAO);/*创建VAO*/ glGenBuffers(1, &VBO);/*创建VAO*/ glGenBuffers(1, &EBO);/*创建EBO*/ /* 1. 绑定VAO, 再设置顶点属性,到解绑之前,这些上下文属性就都属于这个VAO了,避免了VBO重复执行 */ glBindVertexArray(VAO); /* 2. 把顶点数组复制到缓冲中供OpenGL使用 */ glBindBuffer(GL_ARRAY_BUFFER, VBO); glBufferData(GL_ARRAY_BUFFER, vertexMemSize, vertices, GL_STATIC_DRAW);// other: GL_DYNAMIC_DRAW,GL_STREAM_DRAW /* 3. 复制我们的索引数组到一个索引缓冲中,供OpenGL使用*/ glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO); glBufferData(GL_ELEMENT_ARRAY_BUFFER, indexMemSize, indices, GL_STATIC_DRAW); /* 4. 设置顶点属性指针 */ glVertexAttribPointer(0,3, GL_FLOAT, GL_FALSE, 8 * sizeof(GLfloat), (GLvoid*)NULL); glEnableVertexAttribArray(0 /*position-index*/);/*上面2句设置positon */ glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 8 * sizeof(GLfloat), (GLvoid*)(3*sizeof(GLfloat))); glEnableVertexAttribArray(1 /*color-index*/);//这2句设置color glVertexAttribPointer(2, 2/*dimesions*/, GL_FLOAT, GL_FALSE, 8 * sizeof(GLfloat), (GLvoid*)(6 * sizeof(GLfloat))); glEnableVertexAttribArray(2 /*texture-index*/);//这2句设置texture glBindBuffer(GL_ARRAY_BUFFER, 0); /* 解绑VBO,因为glVertexAttribPointer使用ok了*/ ...... } -
上传纹理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36/* 使用一张图片创建一个texture纹理, 并设置属性 */ GLuint CreateTextureWithImage(const char* texImagePath){ /*纹理1生成*/ GLuint texture; glGenTextures(1, &texture); glBindTexture(GL_TEXTURE_2D, texture); /*设置纹理1的环绕方式:GL_REPEAT|GL_MIRRORED_REPEAT|GL_CLAMP_TO_EDGE|GL_CLAMP_TO_BORDER*/ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_MIRRORED_REPEAT); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_MIRRORED_REPEAT); /*设置纹理1过滤(纹理和物体大小不匹配:放大(Magnify)和缩小的时候可以设置纹理过滤选项)*/ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); /*设置多级渐远纹理1 Mipmap(原纹理的1/4,1/16,1/64...来适配远近纹理)*/ /*生成mipmap: glGenerateMipmaps,只有缩小纹理过滤才能mipmap*/ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR); /*使用SOIL库(Simple OpenGL Image Library)加载和创建纹理*/ int texWidth, texHeight; unsigned char* image = SOIL_load_image(texImagePath, &texWidth, &texHeight, 0, SOIL_LOAD_RGB); assert(image!= nullptr); glTexImage2D(GL_TEXTURE_2D,/* 纹理目标(Target)*/ 0, /*Mipmap的级别, 0表示基本级别 */ GL_RGB, /*纹理储存格式 */ texWidth, texHeight, 0, /*历史遗留问题,必须为0 */ GL_RGB, /*原图的格式和数据类型,用RGB加载image */ GL_UNSIGNED_BYTE, image); /*图像数据buffer */ glGenerateMipmap(GL_TEXTURE_2D); SOIL_free_image_data(image); return texture; } -
Shader Compile/Load
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37const GLchar * vShaderCode = vertexCode.c_str();/* 读入了 vertex shader内容的字符串*/ const GLchar * fShaderCode = fragmentCode.c_str();/*读入了 fragment shader内容的字符串 */ /*Step 2.compile vertex-Shader*/ GLuint vertex; GLint success; GLchar infoLog[512]; // vertex shader vertex = glCreateShader(GL_VERTEX_SHADER); glShaderSource(vertex, 1, &vShaderCode, NULL); glCompileShader(vertex); // if has compile error, get and print glGetShaderiv(vertex, GL_COMPILE_STATUS, &success); if (!success){ glGetShaderInfoLog(vertex, 512, NULL, infoLog); std::cout << "ERROR:SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog << std::endl; } /*Step 3.compile fragment-Shader*/ GLuint fragment; fragment = glCreateShader(GL_FRAGMENT_SHADER); glShaderSource(fragment, 1,&fShaderCode, NULL); glCompileShader(fragment); // if has compile error, get and print glGetShaderiv(fragment, GL_COMPILE_STATUS, &success); if (!success){ glGetShaderInfoLog(fragment, 512, NULL, infoLog); std::cout << "ERROR::SHADER::FRAGMENT::COMPILATION_FAILED\n" << infoLog << std::endl; } /*Step 4.Create shader program*/ this->Program = glCreateProgram(); glAttachShader(this->Program, vertex); glAttachShader(this->Program, fragment); glLinkProgram(this->Program); // if has link error, get and print glGetProgramiv(this->Program, GL_LINK_STATUS, &success); ...... -
Uniform 变量传入/绑定 Shader
1 2 3 4 5 6 7 8/*uniform 值设置纹理单元属性 */ glActiveTexture(GL_TEXTURE0); glBindTexture(GL_TEXTURE_2D, texture1); glUniform1i(glGetUniformLocation(shader.GetProgram(), "ourTexture1"), 0); glActiveTexture(GL_TEXTURE1); glBindTexture(GL_TEXTURE_2D, texture2); glUniform1i(glGetUniformLocation(shader.GetProgram(), "ourTexture2"), 1); glUniform1i(glGetUniformLocation(shader.GetProgram(), "textureAlpha"), gTextureAlpha);Unitform 绑定变量后,可以在shader中启用变量并生效:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26// Vertex Shader, 这段存为 vertex.glsl 文件 #version 330 core layout (location = 0) in vec3 position;/*接收来自VBO的数据,并且自行命名*/ layout (location = 1) in vec3 color; layout (location = 2) in vec2 texCoord; out vec3 ourColor; out vec2 TexCoord; uniform mat4 transform; void main() { gl_Position = transform * vec4(position,1.0f); ourColor = color; TexCoord = vec2(texCoord.x, 1.0f - texCoord.y);/*上下翻转,可以改变纹理的朝向*/ } // fragment shader , 这段存为 fragment.glsl 文件 #version 330 core in vec3 ourColor; in vec2 TexCoord; out vec4 color; uniform sampler2D ourTexture1; uniform sampler2D ourTexture2; uniform int textureAlpha; void main() { /*效果4: 加载2个纹理texture1和texture2,且纹理2的透明度可调*/ color = mix(texture(ourTexture1,TexCoord),texture(ourTexture2,vec2(1-TexCoord.x,TexCoord.y)),textureAlpha/100.0);//textureAlpha/100.0 means 2nd texture rate } -
Model 变换
1 2 3 4 5 6 7 8 9/* 注意, 由于矩阵乘法计算规则,实际的变换动作顺序应该与阅读顺序相反 */ /* 实际变换矩阵:先缩放、后旋转、最后平移 */ glm::mat4 CalcTransformMatrix(glm::vec3 translate, glm::vec3 rotateAxis, float rotateAngle, glm::vec3 scale){ glm::mat4 trans(1.0);/*初始化为单位矩阵*/ trans = glm::translate(trans, translate);/*三个方向的平移*/ trans = glm::rotate(trans, rotateAngle, rotateAxis);/*给定的旋转轴以及旋转角*/ trans = glm::scale(trans, scale);/* 三个方向的缩放因子*/ return trans; } -
发起 Draw Call
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23GLFWwindow* window = glfwCreateWindow(width, height, "LearnOpenGL", nullptr, nullptr); ... /*第一个变换图*/ trans = CalcTransformMatrix(glm::vec3(0.5f, 0.5f, 0.0f), glm::vec3(0.0f, 0.0f, 1.0f), glm::radians(static_cast<GLfloat>(glfwGetTime() * 50.0f)), glm::vec3(0.5, 0.5, 0.5)); GLuint transformLoc = glGetUniformLocation(shader.GetProgram(), "transform"); glUniformMatrix4fv(transformLoc, 1, GL_FALSE, glm::value_ptr(trans)); glBindVertexArray(VAO);/*绑定VAO,应用前面设置的属性*/ glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);/*利用顶点索引作图*/ /*第二个变换图, 再次调用glDrawElements */ GLfloat scaleFactor = abs(sin(glfwGetTime())); trans = CalcTransformMatrix(glm::vec3(-0.5f, 0.5f, 0.0f), glm::vec3(0.0f, 0.0f, 1.0f), 0.0f, glm::vec3(scaleFactor, scaleFactor, scaleFactor)); transformLoc = glGetUniformLocation(shader.GetProgram(), "transform"); glUniformMatrix4fv(transformLoc, 1, GL_FALSE, glm::value_ptr(trans)); glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0); glBindVertexArray(0);/*解绑VAO */ ... glfwSwapBuffers(window);// Swap the screen buffers
以上就是一次简单且完整的渲染流程了。